
Memory 技术日报 2026-06-17:KV 擦除、cache continuity、Redis Iris
本期筛出 3 条 memory 方向进展:KVEraser 研究如何在 KV cache 中局部擦除错误上下文,TokenPilot 把上下文压缩和 prompt cache continuity 放到同一框架,Redis Iris 展示企业 agent memory 与语义缓存、数据入口打包的产品路线。读完可判断今天该跟进 KV cache 编辑、长会话成本优化还是企业上下文平台。

리서치 브리프
本期按 2026-06-16 01:00 至 2026-06-17 01:00(Asia/Shanghai)筛选。今天合格信号不多,但三条都贴近线上 memory 系统:KV cache 不只是复用对象,也开始被「定点擦除」和「不破坏 prefix cache 地压缩上下文」;产品侧则把 agent memory、语义缓存和企业数据入口打包成一套上下文平台。
速览
| 方向 | 今天的信号 | 对工程团队的含义 |
|---|---|---|
| KV cache 局部擦除 | KVEraser 提出在已处理上下文中删除指定 span 时,只替换被擦除区间的 KV states,而不是重算后续全部 token;论文称在 1K--32K 上接近 full recomputation,延迟只增加 24%,而 full recomputation 增加 17.6x 1 | RAG 取回了旧事实、工具返回错观察、用户撤回偏好时,未来可能不必把整段后缀全部重跑。 |
| 长会话上下文压缩 | TokenPilot 把 token footprint 和 prompt cache continuity 放在同一问题里处理;论文报告在 PinchBench、Claw-Eval 上 isolated 模式成本下降 61% / 56%,continuous 模式下降 61% / 87% 2 | 做长会话 agent 成本优化时,不能只看删了多少 token,还要看删完后 prefix cache 是否还能命中。 |
| 企业上下文平台 | Redis 发布 Redis Iris 上手教程,页面显示日期为 June 16, 2026;Iris 把 Context Retriever、Agent Memory、RDI、LangCache 和 Redis Search 组合成面向 agent 的 context/memory 平台 3 | 外部记忆正在从「一个向量库 + 几段摘要」变成「数据入口、短长期记忆、缓存、权限和检索」的组合产品。 |
1. KVEraser:KV cache 也需要「删除键」
KVEraser 盯住了一个经常被工程实现绕开的场景:上下文已经 prefill 完,之后才发现中间某段应该删除。原因可能是过期检索结果、错误工具观察、用户撤回的偏好,也可能是 prompt injection。论文指出,精确删除通常要重算被删 span 之后的所有 token,因为它的影响已经传播到后续 cached states 1。
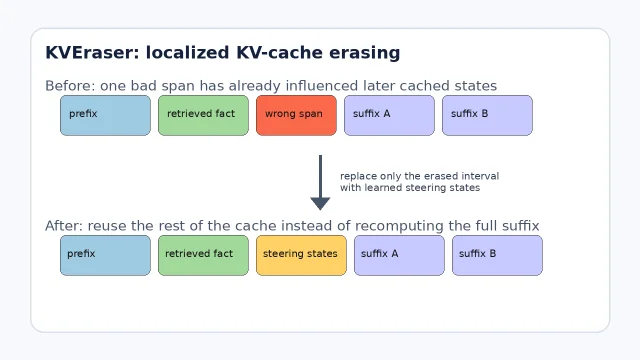
它的做法不是剪文本后重跑,而是训练一个 eraser,用 learned steering states 替换被擦除区间的 KV states,其余 cache 继续复用。训练分两段:先用 span-neighbor pre-training 学会压制被删 span 的影响,再用 task-specific fine-tuning 适配下游场景 1。
工程判断:这条线适合做 retrieval-heavy agent、浏览器 agent 和客服 agent 的团队跟进。只要系统允许外部数据写进上下文,就会遇到「写进去之后才发现不该信」的问题。现在多数系统只能回滚整轮或重放后续上下文,KVEraser 给了一个更细粒度的研究方向。
2. TokenPilot:省 token 不能把 prompt cache 省没了
TokenPilot 的问题定义很像真实 agent 长会话:历史越长,推理越贵;但如果随意剪裁或动态 eviction,序列布局会改变,prefix mismatch 会让 prompt cache 失效 2。所以它不是单纯做上下文压缩,而是在「文本稀疏化」和「缓存连续性」之间做约束。
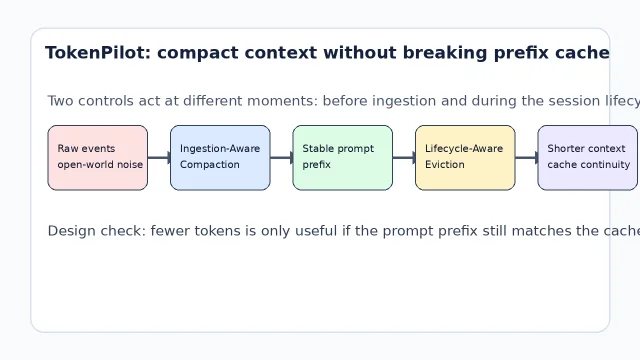
论文把框架拆成两层。全局层 Ingestion-Aware Compaction 在上下文进入前稳定 prompt prefix,并过滤开放环境噪声;局部层 Lifecycle-Aware Eviction 观察 context segment 的剩余效用,用保守的 batch-turn schedule 等任务相关性过期后再卸载内容段。作者还写到,TokenPilot 已集成到 LightMem2 2。
工程判断:如果你已经为 Claude、Gemini 或自托管模型接了 prompt caching,普通 summarization 未必是最优解。摘要让输入变短,但如果它改变了 prefix,prefill 成本可能又回来了。TokenPilot 值得作为「上下文压缩是否 cache-aware」的检查清单。
3. Redis Iris:memory 产品开始和数据入口、语义缓存绑定
Redis Iris 这篇教程不是论文,但它透露了产品侧的包装方式。页面把 Iris 定义为给 AI agents 提供 live、accurate、navigable data 的 context and memory platform,并列出五个组件:Context Retriever、Agent Memory、Redis Data Integration、LangCache、Redis Search 3。
它把三类常见工程需求放到同一个教程里:LangCache 用语义相似度复用 LLM response;Agent Memory 管理 session short-term memory 和 long-term durable memory;Context Retriever 基于业务实体语义模型生成 MCP tools,让 agent 用 scoped keys 和 row-level security 查询企业数据 3。
工程判断:如果你在企业里做 agent memory,先别急着只评估「哪个向量库召回更准」。真正难落地的部分往往是热数据如何同步、缓存如何省成本、用户记忆如何分短期和长期、agent 查询企业数据时权限怎么收口。Redis Iris 的价值在于把这些问题放到同一个控制面里。
今天该跟进什么
- 做 KV cache / long-context serving:先读 KVEraser。它把「删除已进入 cache 的错误上下文」变成可研究的问题,而不是把重算当默认答案。
- 做长会话 agent 成本优化:读 TokenPilot。重点看它怎样保护 prompt cache continuity,而不是只看压缩比例。
- 做企业 agent 平台:浏览 Redis Iris 教程。它更像产品路线信号:memory、semantic cache、MCP 数据入口和权限会被打包销售,也会被客户一起验收。
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.